


Lets get lazy with Polars
Polars series, and more on #edition22

What’s on the list today?
Polars series - Part 2: Lazy API

🐻Polars series - Part 2: Lazy Execution
This is the second part of the Polars series. If you're just starting, please check out Part-1. For those interested in following along, the repository is now available to explore further Github-Polarexpress
Eager vs Lazy API?
Eager and Lazy represent the supported modes of operation in Polars. In the Eager API, a query is immediately executed, whereas in the Lazy API, execution is deferred until an action is called. This deferring of execution results in a significant performance gain and is also the go-to mode for using Polars data frames. Interestingly, this approach is similar to Spark's lazy evaluation, where Spark defers execution by default until an action like count is called on it.
import polars as pl
df_flights = pl.read_parquet("data/flights.parquet")
df_flights = (df_flights.filter(pl.col("dep_delay")>60)
.select("carrier","flight","dep_delay","origin","dest"))
df_agg = df_flights.group_by("carrier").agg(pl.col("dep_delay").mean())
print(df_agg)In this example, we read a Parquet file, apply a filter, and then perform an aggregation. The key point here is that we're using the read_parquet method, which is an Eager API operation, and this results in each subsequent operation being executed immediately. This leads to wasteful resource consumption.
To turn this into a Lazy operation, simply use scan_parquet instead. This will enable lazy evaluation for the same set of operations, which will benefit from it. The query planner and optimizer will analyze the chain of operations and attempt to optimize it in the best possible way. In our example, two benefits exist:
Predicate pushdown: The filter to get only flights with a departure delay of more than 60 minutes is applied as early as possible.
Projection pushdown: Selecting only the columns that are needed will also eliminate the need to load additional data.
df_flights = pl.scan_parquet("data/flights.parquet")
df_flights = (df_flights.filter(pl.col("dep_delay")>60)
.select("carrier","flight","dep_delay","origin","dest"))
df_agg = df_flights.group_by("carrier").agg(pl.col("dep_delay").mean())
df_agg.collect()As implied by the definition, lazy operations are only executed when an action is called, such as collect in this case.
There is a long list of query optimizations that Polars can apply when using the Lazy API. You can find them here: Lazy optimizations
Query Plan
If you're a big SQL buff, you know that accessing the query plan is one of the most pivotal steps in optimizing a query. Thankfully, in Polars, the query plan can be printed using the keyword explain on the DataFrame or LazyFrame.
For any lazy query, Polars can show both a non-optimized query plan as you built the query and an optimized plan with the changes made by the optimizer.
To access the query plan, you can call explain on the LazyFrame, passing the argument optimized=False to view the non-optimized 'as-is' query plan."
df_agg.explain(optimized=False)
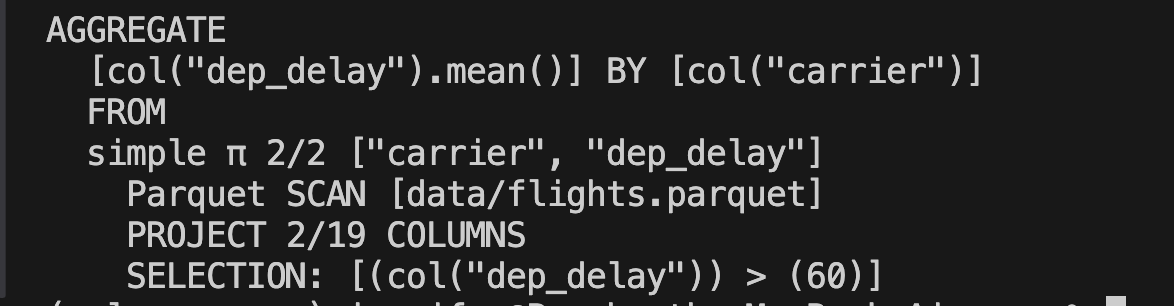
df_agg.explain()For our flights dataset example, the optimized query plan looks like this. From this, we clearly see that the optimizer used predicate pushdown to the lowest level to read only records where dep_delay is more than 60. This kind of optimization is substantial for efficiently using the resources at hand, and that's where Polars excels.
When to use Eager or Lazy execution?
In Richie Wink's own words, "We made the Eager API because we recognize that interactive programming and data exploration are valuable to people." Therefore, the answer is quite straightforward!
Use the Eager API for data exploration.
Use the Lazy API for other cases, including production pipelines.
An important benefit of using Lazy execution is schema awareness. This allows the query engine to report any schema issues, such as unsupported operations on a certain data type, before actually processing any data, thereby avoiding wasteful resource consumption.
Thanks for checking out part-2 of the series. Stay tuned for the next one. The example code is available on Github.